El desarrollo de tecnologías innovadoras requiere de distintos insumos para convertir las ideas en realidad. En el campo de la inteligencia artificial (IA), esta necesidad se traduce en recursos informáticos y costos de infraestructura. Y muchas veces esos insumos, para algunas grandes empresas como Meta, están al alcance de un click. Son, por ejemplo, los datos de sus usuarios. De hecho, la compañía propietaria de Facebook e Instagram, las redes sociales más utilizadas del mundo, ya comenzó a desplegar su asistente inteligente en algunos países para entrenar a sus chatbots. Pero esa puja por la información genera preocupación ante regulaciones claras. ¿Cómo Meta usa mis publicaciones y cómo proteger mis datos y privacidad?
Para modelos de aprendizaje profundo que involucran redes neuronales complejas, una de las tecnologías que dieron vida a chatbots como ChatGPT y otros de su tipo, se necesitan –entre otros elementos y recursos humanos– equipos con alta capacidad de cómputo, que combinan la potencia de múltiples unidades de procesamiento gráfico (GPUs, por sus siglas en inglés), y datasets que almacenan toda la información con la que se alimentan los asistentes inteligentes.
Es allí, en el terreno de la información, en donde las grandes compañías tecnológicas están lidiando con una de las principales encrucijadas para escalar sus modelos grandes de lenguaje (o LLMs), una tarea que involucra recopilar miles de millones de parámetros para mejorar la capacidad de generación de respuestas y su precisión. Para cumplir este requisito, cada empresa se sirve de los datos que tiene a su alcance.
Pero la información, aún en el universo digital al que se accede vía internet, sigue siendo un recurso finito. Según un estudio del instituto de investigación Epoch AI, las compañías tecnológicas podrían quedarse sin información de alta calidad en la web entre 2026 y 2032, una proyección que tiene en cuenta el ritmo actual que sigue la demanda de datos que, remarcan los autores, rebasa al de producción de los contenidos generados por humanos y utilizados para entrenar modelos (incluyendo libros y documentos, entre otros formatos).

Una opción que no resulta del todo atractiva es la de entrenar modelos con información generada por ellos mismos, algo que puede dar lugar a que las alucinaciones –respuestas con información incorrecta o falsa– refuercen la mala calidad de los resultados generados. Mientras que obtener esa información de plataformas que la difunden de manera pública, como medios de comunicación, ha desatado conflictos legales por reclamos de propiedad intelectual.
Es por esto que las corporaciones tecnológicas salen a la búsqueda de nuevas bases de datos para ampliar el conocimiento de sus modelos. En el caso de Meta, el New York Times reveló que la empresa analizó el año pasado la posibilidad de comprar una de las editoriales más grandes del mundo, Simon & Schuster, para acceder a su repositorio de títulos, entre los que se encuentran obras de Stephen King, entre otros autores.
Tal y como hicieron OpenAI y Google con GPT y Gemini (sus respectivos modelos), Meta se encargó de desarrollar los suyos para integrar IA generativa en sus distintos productos, que incluyen redes sociales utilizadas por millones de usuarios en todo el mundo, plataformas en las que hay información valiosa para la exFacebook.
Qué es Llama y cómo usa Meta su IA
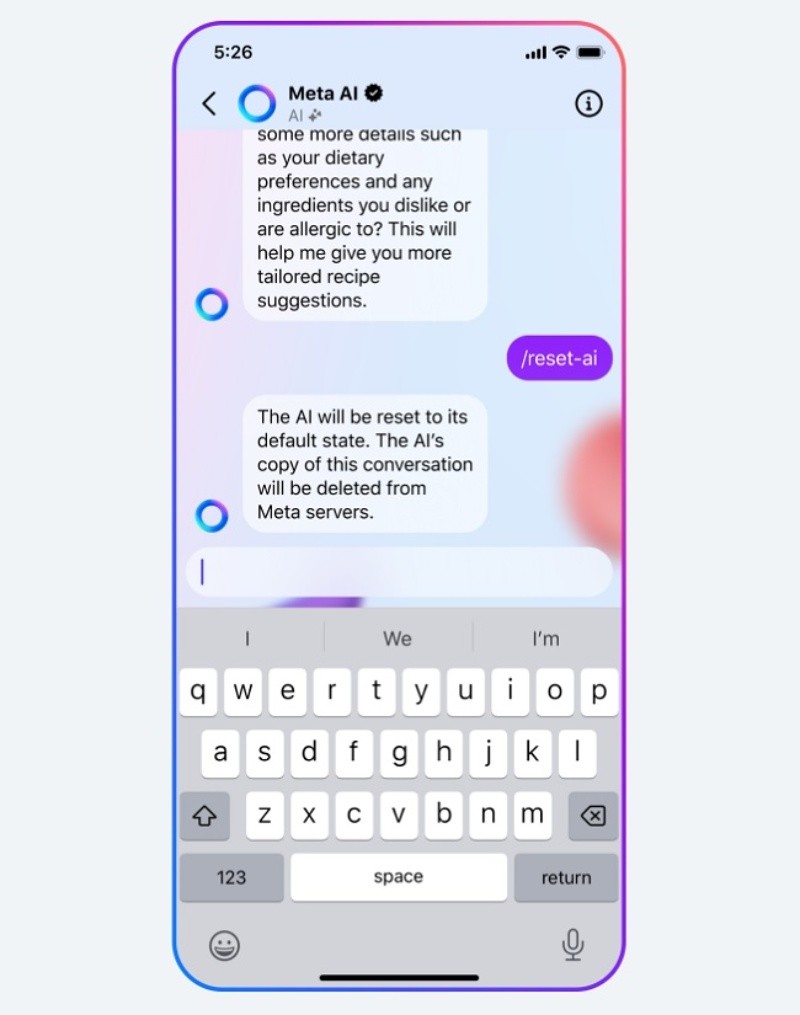
Llama es la denominación que la empresa dirigida por Mark Zuckerberg eligió para sus modelos multimodales, un tipo de aplicación de la IA para los que se combinan diferentes tipos de entradas, como texto, imágenes o videos, y que generan respuestas también en distintos formatos. Llama integra distintos modelos desarrollados por Meta y ha tenido tres iteraciones hasta la fecha. La más reciente se oficializó en abril, cuando la tecnológica anunció públicamente el lanzamiento de Llama 3, versión a la que definieron como capaz de llevar a cabo “razonamiento complejo, seguir instrucciones, visualizar ideas y resolver problemas". En su sitio oficial, Meta indica que “la serie de modelos Llama se lanzó con la premisa de que fueran de código abierto, y de entrenarlos también con información (datasets) disponibles públicamente”. En el caso de Llama 3, el modelo tiene una versión de hasta 70 billones de parámetros, lo que se refiere a los datos que le permiten contextualizar sus respuestas y mejorar sus capacidades predictivas. Llama 3 es el cerebro detrás de Meta AI, el chatbot que la compañía ya habilitó en sus aplicaciones para los países en los que recolectaron datos. En Facebook, Instagram o WhatsApp, los usuarios pueden hacerle consultas de todo tipo a este chatbot, al igual que con ChatGPT, e incluso pedirle que genere imágenes. Este avance concreto de la IA que se convierte en nuevas funciones para los usuarios sumó un nuevo apartado a la discusión sobre la privacidad online, pero el uso de los datos para su entrenamiento inició tiempo antes. En una publicación del 2023, Meta se refirió al entrenamiento de la versión anterior de este modelo y detalló que se habían utilizado "publicaciones compartidas públicamente de Instagram y Facebook (incluidas fotos y texto)". Aunque aclaró: "No entrenamos estos modelos utilizando las publicaciones privadas de las personas. Tampoco utilizamos el contenido de sus mensajes privados con amigos y familiares para entrenar nuestras IA". Lo que sí utilizan, además de lo ya mencionado, son los intercambios entre los usuarios y el chatbot, por lo recomiendan no hacer consultas que incluyan información sensible y que no quiera entregarse. También se sirvieron de datos de terceros, como la organización Common Crawl –que recopila información de la web y la mantiene en repositorios de libre acceso–, GitHub, Wikipedia y libros, entre otras fuentes. Las bases de datos a partir de las que opera Llama ya se nutren de las publicaciones de los usuarios de Facebook e Instagram en algunos países, y sus creadores esperan capturar más datos en otras regiones. A fines de mayo, usuarios de Europa que utilizan ambas plataformas recibieron una notificación en sus cuentas con la que la compañía les informaba que, a partir del 26 de junio, su información pasaría a ser utilizada con el mismo objetivo a menos que lo rechazaran, una posibilidad de elección que se abrió a partir de las regulaciones de esa región en materia de protección de datos. Pero en el resto del mundo, incluyendo a la Argentina, la falta de normativas claras para formalizar un control más riguroso de la actividad de las grandes corporaciones tecnológicas les deja un panorama más sencillo para avanzar con la manipulación de información personal para servir a sus propios intereses, como bien ha quedado plasmado desde hace años por los engranajes que mueven la publicidad digital. Y en lo que respecta al entrenamiento de modelos de IA, los riesgos implícitos suponen una profundización del avance sobre la privacidad. "El uso de datos personales en el entrenamiento de modelos de IA supone un riesgo grande para la privacidad de esos datos, porque al ser usados como insumo de entrenamiento, la IA no tiene un criterio de protección de los mismos", describe María Beatriz Busaniche, presidenta de la Fundación Vía Libre, una organización civil sin fines de lucro que se dedica a promover y defender derechos fundamentales en entornos mediados por tecnologías digitales. Al incorporarse como insumo para las respuestas de estos modelos, esos datos "pueden aparecer en búsquedas que se hagan sobre la persona o, en otras circunstancias, ser usados más allá de los permisos otorgados en el acto de consentimiento", es decir, que “sean explotados más allá del consentimiento otorgado a la empresa”, agrega, consultada por Rosario3, la activista y especialista en derechos y tecnologías digitales. El objetivo de Meta, según comunicaron oficialmente, es utilizar esta información para mejorar y desarrollar sus tecnologías de IA, una potestad que está incluida discrecionalmente en los términos y condiciones de sus plataformas, en donde mencionan que los posteos de los usuarios pueden ser utilizados por los desarrolladores para "investigar e innovar en pos del bienestar social" con el objetivo de "fomentar el avance de la tecnología". En otro apartado, indica también que esa información pueden utilizarla para “probar nuevos productos y funciones”. Al respecto, Busaniche explica: "El margen que le queda a los usuarios de estas plataformas es abandonarlas. El tipo de contrato de adhesión que se acepta al suscribirse a uno de estos servicios contiene este tipo de cláusulas que habilitan a la empresa a usar los datos. En cualquier caso, las autorizaciones a la empresa exceden las medidas de privacidad que se usan para otros usuarios de la plataforma. Por más que usemos la configuración de máxima privacidad, la empresa tiene acceso a todo lo que publicamos". Pero dado que la decisión de no utilizar redes sociales queda descartada para muchas personas, la especialista suma algunas consideraciones para resguardar la privacidad: "Es recomendable en primer lugar no publicar datos ni fotografías de menores de edad o de personas que explícitamente no nos hayan autorizado a hacerlo. Evitar también la publicación de información privada sensible, es decir, tener un control estricto sobre lo que se publica, porque debe ser sólo lo que estemos dispuestos a resignar en materia de privacidad". El despliegue de Meta AI se ha hecho, hasta el momento, en Estados Unidos y otros 13 países: Australia, Canadá, Ghana, Jamaica, Malawi, Nueva Zelanda, Nigeria, Pakistán, Singapur, Sudáfrica, Uganda, Zambia, y Zimbabwe. En todos los casos, la opción que se le da a los usuarios es la de corregir o eliminar información que esté incluida en las respuestas del chatbot, pero lo concreto es que los datos ya fueron incorporados al modelo. Por su parte, los usuarios europeos tienen la posibilidad de solicitar y completar un formulario para que sus datos no sean utilizados en el entrenamiento de los modelos de Meta AI. A su vez, de manera diferencial se habilitó una opción de configuración para los países que integran el bloque de la Unión Europea. Desde esa región se puede acceder a un apartado en el que se ofrece la posibilidad de desactivar las configuraciones de "compartir datos" y también una para que esa información no permanezca en los modelos de IA. Estas opciones se encuentran en el Centro de Privacidad de Meta, concretamente en el apartado de administración de datos en la sección de "actividad fuera de Facebook". A su vez, se puede enviar una solicitud para ejercer los derechos declarados en el Reglamento General de Protección de Datos de la Unión Europea, en la que se debe incluir una justificación. Ya situados en Argentina, la falta de regulaciones concretas sobre esta tema no le deja muchas opciones a los usuarios, que en sus configuraciones de privacidad no pueden poner al resguardo su información personal en este sentido. Si bien hay otras opciones, en lo que respecta al entrenamiento de modelos de IA no se ofrecen herramientas de decisión, aunque cabe mencionar que Meta AI todavía no está disponible en la región. En el apartado de administración de datos del "Centro de privacidad" de Meta, desde donde se configuran las preferencias para Facebook e Instagram, no dice nada sobre quitar la información personal para su uso para el entrenamiento de modelos. Solo ofrece enlaces a las distintas secciones de Facebook para consultar sus diferentes políticas de uso de la información. En las Condiciones del servicio de la IA de Meta, la compañía establece lo siguiente: "Según dónde residas, tú o un representante autorizado pueden solicitarle a Meta acceso a tu información personal en un formato portátil, la eliminación de tu información personal o la corrección de tu información personal, sujeto a ciertas excepciones". Esa solicitud se gestiona desde esta página. Frente a la incertidumbre, cabe suponer que cuando Meta AI esté disponible en el país cada usuario podrá eliminar información particular interactuando con el chatbot, como ocurre en los casos mencionados. Pero, de momento, establecer una barrera previa para que esos datos no lleguen a los datasets no es posible y solo quedan dos opciones. Por un lado, en la ventana de chat de Meta AI se puede usar el comando /reset-ai para borrar el historial de la conversación y su información, que según Meta no se vincula directamente con cada cuenta, pero sí se usa para brindar respuestas personalizadas. De esta forma se borrará "cualquier detalle guardado sobre ti que hayas compartido en ese chat" y la IA "no recordará los mensajes anteriores". Otro comando, /reset-all-ais, "se puede escribir en cualquier chat individual que mantengas con una IA en Messenger, Instagram o WhatsApp" para restablecer "todas las IA, incluidas las de los chats en grupo en los que participas", indican desde la plataforma en la sección "Cómo cambiar o eliminar tu información de los chats con IA de Meta”. Más allá de esa herramienta, Busaniche remarcó que la recomendación es "dejar de entregar información de forma gratuita para estas empresas", lo que implica ser más conscientes sobre lo que compartimos en redes sociales. “Los datos de entrenamiento, esos grandes volúmenes de información que se usan para entrenar los modelos, son un insumo extremadamente valioso. Estamos regalando figuritas a cambio de nada", expresó la especialista. También hizo hincapié en que "la discusión regulatoria en Argentina está atrasada" y que la normativa vigente no es clara en cuanto a las condiciones de manejo de los datos. "Hay un proyecto de actualización de la Ley 25.326 de Protección de Datos Personales", sobre la cual "es posible hacer diversas interpretaciones". "Una interpretación de la ley vigente nos permitiría afirmar que si este uso no está explícitamente declarado en los términos del contrato de adhesión con la empresa, es un uso no consentido y por tanto requeriría nuevo consentimiento y una definición clara de la finalidad de su recolección. Sin embargo, si hay una autorización laxa de uso, es complejo hacer cumplir esos derechos en el marco de estos contratos de adhesión sin una autoridad de aplicación que se ponga a trabajar en defender los derechos de la gente", explicó.
Las regulaciones son, precisamente, lo que le impone un marco normativo a estas compañías que, de lo contrario, se rigen solo por las políticas de uso que ellos mismos definen para los usuarios que utilizan sus productos. El caso europeo da cuenta de que con una normativa específica se puede ejercer un control más riguroso sobre la manipulación de datos personales. Entre otros puntos, dicho reglamento exige una Evaluación de Impacto de la Protección de Datos cada vez que se inicia un nuevo proyecto que implique "un alto riesgo" para la información personal de otras personas, y aunque no prohibe explícitamente este tipo de utilización de los datos personales, sí indica que los usuarios tienen el derecho a objetarse. Este marco impulsó, durante las últimas semanas, quejas de más de una decena de países de la Unión Europea contra Meta por su uso de los datos personales, que fueron presentadas a partir de un pedido del grupo de defensa de la privacidad None of Your Business (NYOB). Max Schrems, fundador de NYOB, señaló en una declaración que es completamente irrazonable confiar a los usuarios la responsabilidad de proteger su privacidad, y enfatizó en que si Meta quiere usar los datos de los usuarios, debe pedir permiso directamente. En su lugar, la empresa ha hecho que los usuarios soliciten ser excluidos del uso de datos. We (@NOYBeu) filed 11 complaints today against @MetaAI's attempt to just use all public and private data (other than chats) of roughly 400 million European users for unspecified current and future "AI technology". We asked for an urgency perocedure.https://t.co/U52U7CyNh3 Esta situación parece haber retrasado los planes de Meta en la región. En una publicación en su sitio oficial, la empresa señala que tiene planeado habilitar estas herramientas durante este año, pero aclaran: “Para servir adecuadamente a nuestras comunidades europeas, los modelos que impulsan la IA en Meta deben capacitarse con información relevante que refleje los diversos idiomas, geografía y referencias culturales de las personas en Europa que los utilizarán. Para hacer esto, queremos entrenar nuestros grandes modelos de lenguaje que potencian las funciones de IA utilizando el contenido que las personas en la UE han elegido compartir públicamente en los productos y servicios de Meta". Incluso apuntan contra empresas como Google y OpenAI, que "ya han utilizado datos de usuarios europeos para entrenar la IA", y sostienen que en su caso la IA no está "diseñada para identificar a ningún individuo". El texto concluye planteando interrogantes para desafiar las regulaciones, preguntando si "tendrán los europeos el mismo acceso a una IA innovadora" que otros países, y planteando un escenario en el que la región se quedará viendo "cómo el resto del mundo se beneficia de una tecnología verdaderamente innovadora". La innovación que promulga Meta, y lo mismo aplica para las empresas con las que compite en el campo de la IA, parece no estar del todo alineada con dos de los cinco pilares para una IA responsable que dicen sostener desde la firma propietaria de las redes sociales más utilzadas en el mundo: "privacidad y seguridad" y "transparencia y control". En este escenario, la disputa sigue siendo cómo sostener la innovación sin que ello implique un perjuicio para los usuarios.
Sin margen para la privacidad
Entre la falta de opciones y la resignación
¿Se puede evitar que mis datos personales se usen para entrenar la IA de Meta?
Regulaciones que "chocan" con la innovación